

In dieser dreiteiligen Blog-Serie behandeln wir VP9, Skalierbarkeit und den neuen, leistungsfähigeren VP9-Codec von Vidyo. In Teil 1 haben wir die zeitliche Skalierbarkeit besprochen; heute werden wir uns mit der räumlichen Skalierbarkeit beschäftigen.
Mehr lesen - VP9 verbessern, ohne es zu ändern - Teil 1
Die zweite Dimension der Skalierbarkeit ist die räumliche Skalierbarkeit, die etwas komplexer ist. Nehmen wir als Beispiel an, dass wir einen Videostrom mit 720p kodieren (d. h. jedes Bild hat 1280×720 Pixel). Eine skalierbare Kodierung bedeutet, dass wir das Video nicht nur in der höchsten Auflösung von 1280×720 Pixeln, sondern auch in niedrigeren Auflösungen, z. B. 640×360 oder 320×180, darstellen können. Beachten Sie, dass die Auflösungen in diesem Beispiel um Potenzen von 2 in jeder Dimension abnehmen. Dies ist zwar keine Voraussetzung, aber Verhältnisse von 2:1 oder 1,5:1 sind typisch für die räumliche Skalierbarkeit. Die niedrigste Auflösung wird als Basisebene bezeichnet, und die Daten, die zum Aufbau jeder höheren Auflösung benötigt werden, werden als Erweiterungsebenen bezeichnet.
Die Terminologie spiegelt in diesem Fall wider, wie die kodierten Daten aufgebaut sind. Bei der Kodierung eines Bildes skaliert der Kodierer das Originalbild auf die Auflösung der Basisschicht herunter. Dann kodiert er es und verwendet das rekonstruierte Bild (das gleiche Bild, das dem Dekoder zur Verfügung steht) als Referenz für die Kodierung des höher aufgelösten Bildes.
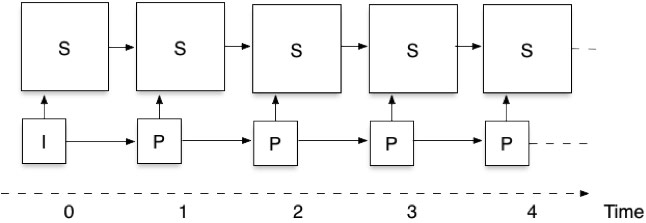
Abbildung 3: Ein Video, das mit zwei räumlichen Ebenen und einer zeitlichen Ebene kodiert ist
Abbildung 3 zeigt die Funktionsweise der Bildstruktur anhand eines Beispiels mit zwei räumlichen Ebenen und ohne zeitliche Skalierbarkeit (es gibt nur eine einzige zeitliche Ebene). Beachten Sie, dass es zwei Gruppen von Bildern oder räumlichen Ebenen gibt. Der unterste Satz sind die Bilder mit niedriger Auflösung (die Basisschicht), die mit der IPPP-Struktur von Abbildung 1. Darüber hinaus gibt es die räumliche Anreicherungsschicht (S), bei der Bilder nicht nur aus früheren Bildern der Anreicherungsschicht, sondern auch aus dem entsprechenden Bild der Basisschicht vorhergesagt werden. Diese Abhängigkeit zwischen den Schichten ist sowohl für die Verbesserung der Komprimierungseffizienz (die niedrig aufgelöste Version eines Bildes ist ein hervorragender Prädiktor für die meisten Teile des hoch aufgelösten Bildes) als auch für die verbesserte Fehlerrobustheit (Sie können immer die niedrig aufgelöste Version verwenden, wenn die hoch aufgelöste beschädigt wird oder verloren geht) sehr wichtig.
Wir können nun die Konzepte der räumlichen und zeitlichen Skalierbarkeit in einem einzigen Entwurf kombinieren und so jede beliebige Kombination von räumlichen Auflösungen und Bildraten ermöglichen. Bleiben wir bei unserem Beispiel mit zwei räumlichen und drei zeitlichen Ebenen, Abbildung 4 zeigt, wie die Bildstruktur aussieht.
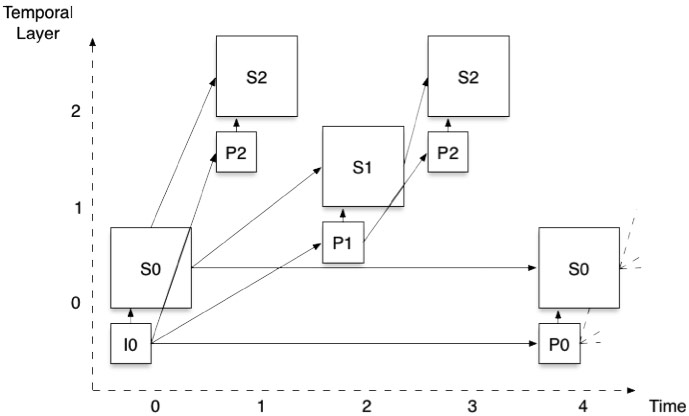
Abbildung 4: Kombinierte Skalierbarkeit: zwei räumliche Ebenen und drei zeitliche Ebenen
Ausgehend von einer 720p-Quelle mit 30 Bildern pro Sekunde können wir mit dieser Struktur Sätze von Ebenen erhalten, die eine beliebige Kombination von 720p oder 360p und 30, 15 und 7,5 Bildern pro Sekunde bieten. Das Wichtigste ist, dass die Dekodierung von einem Qualitätspunkt zum anderen wechseln kann, ohne dass der Kodierer informiert werden muss oder eine Signalverarbeitung erforderlich ist.
Die Anpassungsfähigkeit, die durch die skalierbare Kodierung ermöglicht wird, ist ein wichtiger Bestandteil bei der Implementierung von Multipoint-Video mit der patentierten Selective Forwarding Unit (SFU) Architektur von Vidyo. Die SFU kann das Video durch selektive Weiterleitung von Layer-Daten je nach Benutzer-, Netzwerk- oder Anwendungsanforderungen manipulieren. Skalierbarkeit (sowohl räumlich als auch zeitlich) ist ebenfalls wichtig, um eine erhöhte Fehlerresistenz zu gewährleisten. Weitere Einzelheiten zu den technischen Konstruktionsprinzipien finden Sie unter mein BlogGeek.me Beitrag.
Während die Manipulation eines räumlich und zeitlich skalierbaren Datenstroms sehr einfach ist, ist es die Erstellung eines solchen nicht. Wenn Sie einen Blick auf Abbildung 4Hinter jedem Pfeil, der zwei Bilder oder Ebenen miteinander verbindet, verbergen sich Tausende von Einzelentscheidungen, die vom Encoder getroffen werden müssen. Die Aufgabe des Decoders ist viel einfacher, da er nur auf die Anweisungen des Encoders reagieren muss.
Man kann sich den Encoder als den Musikkomponisten und den Decoder als den Synthesizer vorstellen, der die Musik entsprechend der vom Komponisten erstellten Partitur wiedergibt. Im Gegensatz zu den 88 Tasten eines Keyboards sehen die Parameter eines Encoders jedoch eher wie das Cockpit eines Verkehrsflugzeugs aus (siehe Abbildung 5) - Tausende von Einzelparametern müssen aufeinander abgestimmt werden, damit die Dinge gut funktionieren.

Abbildung 5: A380-800-Cockpit (von der Website der Lufthansa)
Schauen Sie bald wieder vorbei für Teil drei, in dem wir uns mit Leistungsvergleichen und mehr beschäftigen.