


Vidyo ha recentemente annunciato la propria implementazione del codec VP9 scalabile, con significativi miglioramenti in termini di prestazioni ed efficienza rispetto all'implementazione del codec VP9 open-source WebM, soprattutto sui dispositivi mobili. Inoltre, il codec VP9 di Vidyo mantiene la piena compatibilità con WebRTC e con qualsiasi applicazione che utilizza il codec WebM VP9, compreso il browser Chrome di Google. In questa serie di blog in tre parti, spiegherò in modo più dettagliato le caratteristiche e i vantaggi di questo nuovo ed entusiasmante design. Ma prima di farlo, è importante comprendere lo sfondo e il contesto di VP9, della scalabilità e dei codec video in generale.
Il codec video VP9 è diventato disponibile per la prima volta nel browser Google Chrome alla fine del 2015, quando Cromo 48 è stato rilasciato. Sebbene WebRTC richieda notoriamente il supporto di VP8 e H.264 in un browser, VP9 ha introdotto un'alternativa open source e presumibilmente esente da royalty che ha superato sia H.264 che, naturalmente, il più vecchio VP8. In un post sul blog nel dicembre 2015Ho riassunto la storia dello sviluppo di VP9 nel contesto di WebRTC e Google+ Hangouts.
L'importanza di VP9 per la comunicazione in tempo reale va ben oltre il fatto che offre un'efficienza di compressione all'avanguardia in un pacchetto open source e privo di royalty. Come ho scritto nell'aprile del 2016 nel mio post ospite "Scalabilità, VP9 e cosa significa per WebRTC". in BlogGeek.Me, è il primo codec di questo tipo a portare lo stato dell'arte della scalabilità nella comunicazione video basata su browser. La scalabilità si è dimostrata uno strumento essenziale per l'implementazione di video multipoint di alta qualità ed è supportata dagli standard di codec H.264 e HEVC, coperti da royalty.
La codifica scalabile significa che lo stesso flusso di bit video contiene sottoinsiemi di dati, chiamati strati, che consentono di ricostruire l'originale a diverse risoluzioni. La scalabilità può riferirsi a diverse dimensioni: temporale, spaziale o qualitativa; le prime due sono utilizzate nelle applicazioni di comunicazione in tempo reale.
La scalabilità temporale significa che lo stesso flusso di bit video consente di prendere un sottoinsieme dei dati e di rappresentare il video a diverse frequenze di fotogrammi. Figura 1 mostra come viene eseguita la codifica video nella comunicazione in tempo reale quando non viene utilizzata la scalabilità, cioè con un singolo livello. Ogni immagine utilizza l'immagine codificata in precedenza come riferimento; in questo modo il codificatore deve inviare solo la differenza tra le immagini successive, riducendo così la quantità di dati da trasmettere. Queste immagini sono chiamate "P" dalla parola "predicted". La primissima immagine non utilizza la predizione di un'immagine precedente e viene definita immagine intra o "I". Una limitazione è che per decodificare un'immagine è necessario aver ricevuto tutte le immagini precedenti della catena. Questa struttura di codifica delle immagini viene tipicamente chiamata IPPP, dalla sequenza di tipi di immagini da cui è costruita.
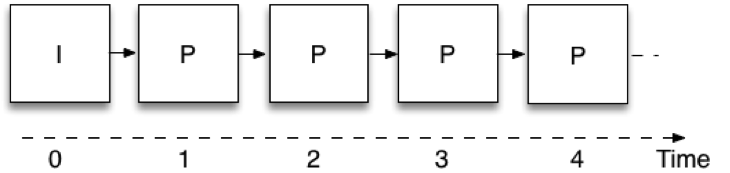
Figura 1: Codifica a singolo strato
Figura 2 mostra come avviene la codifica quando si utilizzano tre livelli temporali. Le immagini sono mostrate con un offset verticale per identificare facilmente i diversi livelli. Supponiamo che il frame rate completo sia di 30 fotogrammi al secondo (fps). Il livello inferiore (livello 0) codifica una immagine ogni quattro, fornendo così una velocità di 7,5 fps. Si noti che questo livello è codificato nello stesso modo in cui è codificato in Figura 1 - la prima immagine è un'immagine I, mentre le immagini successive sono tutte immagini P (P0).
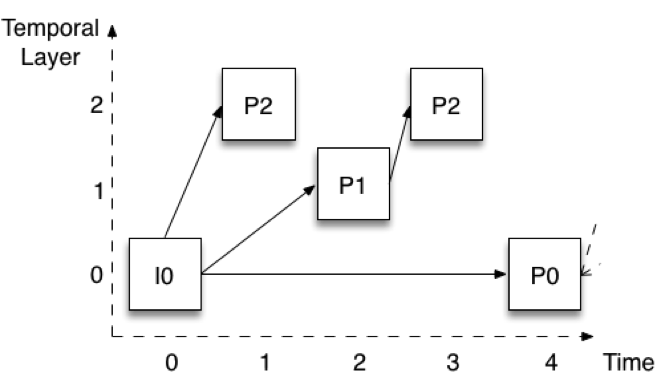
Figura 2: Scalabilità temporale con tre livelli
Il livello 1 viene quindi costruito aggiungendo le immagini che si trovano a metà strada tra le immagini del livello 0. Nella Figura 2 si tratta dell'immagine P1. Nella Figura 2 si tratta dell'immagine P1. Si noti che è codificata utilizzando l'immagine immediatamente precedente del livello 0. Se si aggiungono le immagini P1 a quelle P0, si ottiene una velocità totale di 15 fps. Infine, il livello 2 viene costruito aggiungendo tutte le immagini rimanenti (P2). Anche in questo caso le immagini sono codificate utilizzando le immagini immediatamente precedenti di un livello inferiore. Per la prima P2, ciò significa I0 (o P0 più avanti nel tempo), mentre per la seconda P2 significa la P1 al tempo 2. Se aggiungiamo le immagini P2 a quelle P0 e P1, otteniamo un totale di 30 fps.
Questa struttura, chiamata codifica gerarchica delle immagini P, ha diverse proprietà utili. In primo luogo, è possibile rimuovere gli strati superiori senza compromettere la capacità di decodificare gli strati inferiori. È quindi possibile ridurre la frequenza dei fotogrammi in qualsiasi momento senza alcuna elaborazione del segnale. In secondo luogo, la struttura ci permette anche di passare a un livello temporale superiore in qualsiasi momento. Ad esempio, posso ricevere e decodificare solo il livello 0 a 7,5 fps, ma poi decidere di passare a 30 fps completi e iniziare a farlo senza alcun ritardo o elaborazione aggiuntiva del segnale. La struttura presenta anche una robustezza notevolmente migliorata. Ad esempio, solo il livello 0 deve essere ricevuto in modo affidabile.