

Vidyo hat kürzlich seine eigene Codec-Implementierung von skalierbarem VP9 angekündigt, die im Vergleich zur Open-Source VP9-Codec-Implementierung von WebM erhebliche Leistungs- und Effizienzverbesserungen aufweist, insbesondere auf mobilen Geräten. Darüber hinaus ist der VP9-Codec von Vidyo vollständig kompatibel mit WebRTC und allen Anwendungen, die den WebM VP9-Codec verwenden, einschließlich des Chrome-Browsers von Google. In dieser dreiteiligen Blog-Serie werde ich die Besonderheiten und Vorteile dieses aufregenden neuen Designs näher erläutern. Zuvor ist es jedoch wichtig, den Hintergrund und den Kontext von VP9, Skalierbarkeit und Videocodecs im Allgemeinen zu verstehen.
Der VP9-Videocodec wurde Ende 2015 zum ersten Mal im Google Chrome-Browser verfügbar, als Chrom 48 veröffentlicht wurde. Obwohl WebRTC bekanntlich voraussetzt, dass sowohl VP8 als auch H.264 in einem Browser unterstützt werden, wurde mit VP9 eine quelloffene und angeblich lizenzgebührenfreie Alternative eingeführt, die sowohl H.264 als auch das viel ältere VP8 übertrifft. In einem Blogbeitrag im Dezember 2015habe ich die Geschichte der Entwicklung von VP9 im Zusammenhang mit WebRTC und Google+ Hangouts zusammengefasst.
Die Bedeutung von VP9 für die Echtzeitkommunikation geht weit über die Tatsache hinaus, dass es eine hochmoderne Komprimierungseffizienz in einem quelloffenen, lizenzgebührenfreien Paket bietet. Wie ich bereits im April 2016 in meinem Gastbeitrag schrieb "Skalierbarkeit, VP9 und was das für WebRTC bedeutet" in BlogGeek.Me ist es der erste Codec dieser Art, der modernste Skalierbarkeit in die browserbasierte Videokommunikation bringt. Skalierbarkeit hat sich als wesentliches Werkzeug für die Implementierung von hochwertigem Multipoint-Video erwiesen und wird von den lizenzpflichtigen Codec-Standards H.264 und HEVC unterstützt.
Skalierbare Kodierung bedeutet, dass ein und derselbe Videobitstrom Teilmengen von Daten, so genannte Schichten, enthält, die es ermöglichen, das Original in verschiedenen Auflösungen zu rekonstruieren. Die Skalierbarkeit kann sich auf mehrere Dimensionen beziehen, nämlich auf die zeitliche, die räumliche oder die qualitative Dimension, wobei die ersten beiden Dimensionen in Echtzeitkommunikationsanwendungen verwendet werden.
Zeitliche Skalierbarkeit bedeutet, dass ein und derselbe Videobitstrom die Möglichkeit bietet, eine Teilmenge der Daten zu nehmen und das Video mit unterschiedlichen Bildraten darzustellen. Abbildung 1 zeigt, wie die Videokodierung bei der Echtzeitkommunikation erfolgt, wenn keine Skalierbarkeit verwendet wird, d. h. mit einer einzigen Ebene. Jedes Bild verwendet das zuvor kodierte Bild als Referenz; auf diese Weise muss der Kodierer nur die Differenz zwischen aufeinanderfolgenden Bildern senden, wodurch die zu übertragende Datenmenge reduziert wird. Diese Bilder werden als "P" bezeichnet, abgeleitet von dem Wort "predicted". Das allererste Bild verwendet keine Vorhersage aus einem vorherigen Bild und wird als Intra- oder "I"-Bild bezeichnet. Eine Einschränkung besteht darin, dass man zur Dekodierung eines Bildes alle vorhergehenden Bilder in der Kette empfangen haben muss. Diese Bildcodierungsstruktur wird in der Regel als IPPP bezeichnet, was auf die Abfolge der Bildtypen zurückzuführen ist, aus denen sie aufgebaut ist.
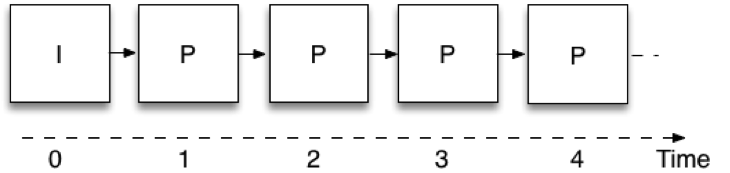
Abbildung 1: Einschichtige Kodierung
Abbildung 2 zeigt, wie die Kodierung erfolgt, wenn drei zeitliche Ebenen verwendet werden. Die Bilder werden mit einem vertikalen Versatz dargestellt, damit die verschiedenen Ebenen leicht zu erkennen sind. Nehmen wir an, die Vollbildrate beträgt 30 Bilder pro Sekunde (fps). Die unterste Ebene (Ebene 0) kodiert eines von vier Bildern, was eine Rate von 7,5 fps ergibt. Beachten Sie, dass diese Ebene auf die gleiche Weise kodiert wird wie in Abbildung 1 - das erste Bild ist ein I-Bild, und die folgenden Bilder sind alle P-Bilder (P0).
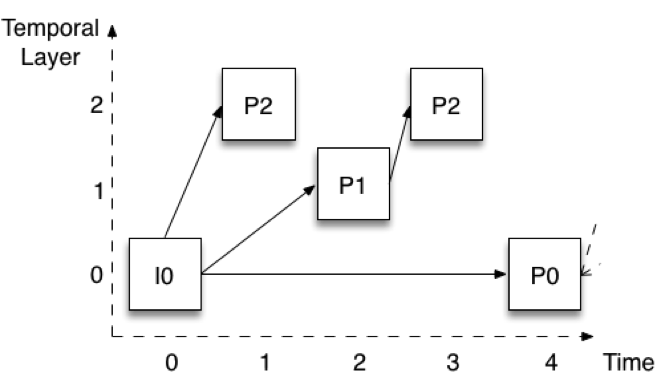
Abbildung 2: Zeitliche Skalierbarkeit mit drei Schichten
Ebene 1 wird dann durch Hinzufügen der Bilder gebildet, die in der Mitte zwischen den Bildern der Ebene 0 liegen. In Abbildung 2 wäre das das Bild P1. Beachten Sie, dass es unter Verwendung des unmittelbar vorhergehenden Bildes der Schicht 0 kodiert wird. Wenn wir die P1-Bilder zu den P0-Bildern hinzufügen, erhalten wir eine Gesamtrate von 15 fps. Schließlich wird die Schicht 2 durch Hinzufügen aller verbleibenden Bilder (P2) aufgebaut. Diese Bilder werden wiederum mit den unmittelbar vorhergehenden Bildern einer niedrigeren Schicht kodiert. Für das erste P2 bedeutet dies I0 (oder P0 zu einem späteren Zeitpunkt), während es sich beim zweiten P2 um das P1 zum Zeitpunkt 2 handelt. Wenn wir die P2-Bilder zu den P0- und P1-Bildern addieren, erhalten wir insgesamt 30 fps.
Diese Struktur, die so genannte hierarchische P-Bild-Codierung, hat mehrere nützliche Eigenschaften. Erstens können wir höhere Schichten entfernen, ohne die Fähigkeit zu beeinträchtigen, niedrigere Schichten zu dekodieren. Es ist dann möglich, die Bildrate zu jedem beliebigen Zeitpunkt ohne Signalverarbeitung zu reduzieren. Zweitens erlaubt uns die Struktur auch, zu jedem beliebigen Zeitpunkt auf eine höhere zeitliche Ebene zu wechseln. Ich kann zum Beispiel nur die Schicht 0 mit 7,5 fps empfangen und dekodieren, dann aber beschließen, auf volle 30 fps umzuschalten, und dies ohne Verzögerung oder zusätzliche Signalverarbeitung tun. Die Struktur hat auch eine deutlich verbesserte Robustheit. So muss beispielsweise nur die Schicht 0 zuverlässig empfangen werden.