

Vidyo a récemment annoncé sa propre implémentation du codec VP9 évolutif, avec des améliorations significatives en termes de performances et d'efficacité par rapport à l'implémentation du codec VP9 open-source WebM, en particulier sur les appareils mobiles. En outre, le codec VP9 de Vidyo reste entièrement compatible avec WebRTC et toute application utilisant le codec VP9 de WebM, y compris le navigateur Chrome de Google. Dans cette série de blogs en trois parties, j'expliquerai plus en détail les spécificités et les avantages de ce nouveau design passionnant. Mais avant cela, il est important de comprendre l'historique et le contexte du VP9, de l'évolutivité et des codecs vidéo en général.
Le codec vidéo VP9 est devenu disponible pour la première fois dans le navigateur Google Chrome à la fin de l'année 2015, lorsque Chrome 48 a été publié. Bien que WebRTC exige que VP8 et H.264 soient pris en charge dans un navigateur, VP9 a introduit une alternative open source et prétendument libre de droits qui surpasse à la fois H.264 et, bien sûr, VP8, beaucoup plus ancien. Dans un article de blog en décembre 2015J'ai résumé l'histoire du développement de VP9 dans le contexte de WebRTC et de Google+ Hangouts.
L'importance de VP9 pour la communication en temps réel va bien au-delà du fait qu'il offre une efficacité de compression de pointe dans un package open source et libre de droits. Comme je l'ai écrit en avril 2016 dans mon billet d'invité "Scalability, VP9, and what it means for WebRTC" (évolutivité, VP9 et ce que cela signifie pour WebRTC) Ce codec est le premier à offrir une évolutivité de pointe dans le domaine de la communication vidéo par navigateur. L'évolutivité s'est révélée être un outil essentiel pour la mise en œuvre d'une vidéo multipoint de haute qualité, et elle est prise en charge par les normes de codecs H.264 et HEVC, qui sont soumises à des droits d'auteur.
Le codage évolutif signifie que le même flux binaire vidéo contient des sous-ensembles de données, appelés couches, qui permettent de reconstruire l'original à différentes résolutions. L'évolutivité peut se référer à un certain nombre de dimensions, à savoir temporelle, spatiale ou qualitative, les deux premières étant utilisées dans les applications de communication en temps réel.
L'évolutivité temporelle signifie que le même flux binaire vidéo permet de prendre un sous-ensemble de données et de représenter la vidéo à différentes fréquences d'images. Figure 1 montre comment le codage vidéo est effectué dans le cadre d'une communication en temps réel lorsque l'évolutivité n'est pas utilisée, c'est-à-dire avec une seule couche. Chaque image utilise l'image codée précédente comme référence ; ainsi, le codeur ne doit envoyer que la différence entre les images successives, ce qui réduit la quantité de données qu'il doit transmettre. Ces images sont appelées "P", du mot "prédit". La toute première image n'utilise pas la prédiction d'une image précédente et est appelée image intra ou "I". Une limitation est que pour décoder une image, il faut avoir reçu toutes les images précédentes de la chaîne. Cette structure de codage d'images est généralement appelée IPPP, d'après la séquence de types d'images à partir de laquelle elle est construite.
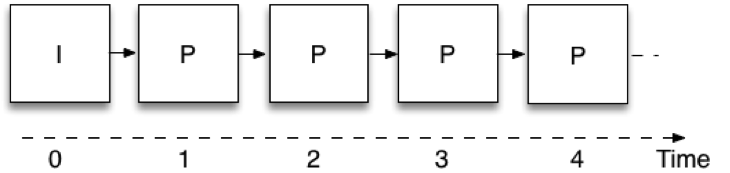
Figure 1 : Codage d'une seule couche
Figure 2 montre comment le codage est effectué lorsque trois couches temporelles sont utilisées. Les images sont présentées avec un décalage vertical pour faciliter l'identification des différentes couches. Supposons que la fréquence d'images complète soit de 30 images par seconde (ips). La couche inférieure (couche 0) code une image sur quatre, ce qui donne une fréquence de 7,5 images par seconde. Remarquez que cette couche est codée de la même manière que dans la couche Figure 1 - la première image est une image I, et les images suivantes sont toutes des images P (P0).
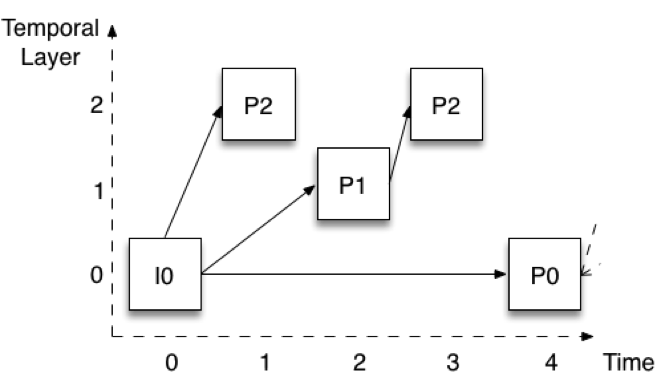
Figure 2 : Extensibilité temporelle avec trois couches
La couche 1 est ensuite construite en ajoutant les images qui se trouvent à mi-chemin entre les images de la couche 0. Dans la figure 2, il s'agit de l'image P1. Remarquez qu'elle est codée en utilisant l'image immédiatement précédente de la couche 0. Si nous ajoutons les images P1 aux images P0, nous obtenons un débit total de 15 images par seconde. Enfin, la couche 2 est construite en ajoutant toutes les images restantes (P2). Ces images sont à nouveau encodées en utilisant les images immédiatement précédentes d'une couche inférieure. Pour la première P2, il s'agit de I0 (ou P0 plus tard dans le temps), tandis que pour la deuxième P2, il s'agit de P1 au temps 2. Si nous ajoutons les images P2 aux images P0 et P1, nous obtenons un total de 30 fps.
Cette structure, appelée codage d'image P hiérarchique, présente plusieurs propriétés utiles. Tout d'abord, nous pouvons supprimer les couches supérieures sans affecter notre capacité à décoder les couches inférieures. Il est alors possible de réduire la fréquence d'images à un moment donné sans traitement du signal. Deuxièmement, la structure nous permet également de passer à une couche temporelle supérieure à tout moment. Par exemple, je peux recevoir et décoder uniquement la couche 0 à 7,5 fps, puis décider de passer à 30 fps et commencer à le faire sans délai ni traitement de signal supplémentaire. La structure présente également une robustesse nettement améliorée. Par exemple, seule la couche 0 doit être reçue de manière fiable.