

Vidyo recently announced its own codec implementation of scalable VP9, with significant performance and efficiency improvements compared to the WebM open-source VP9 codec implementation, especially on mobile devices. Additionally, Vidyo’s VP9 codec maintains full compatibility with WebRTC and any application that uses the WebM VP9 codec, including Google’s Chrome browser. In this three-part blog series, I will explain in more detail the specifics and benefits of this exciting new design. But, before doing that, it is important to first understand the background and context of VP9, scalability and video codecs in general.
The VP9 video codec became available for the first time in the Google Chrome browser in late 2015, when Chrome 48 was released. Although WebRTC famously requires that both VP8 and H.264 are supported in a browser, VP9 introduced an open source and purportedly royalty-free alternative that outperformed both H.264 and, of course, the much older VP8. In a blog post in December 2015, I summarized the history of VP9’s development in the context of WebRTC and Google+ Hangouts.
VP9’s significance for real-time communication goes way beyond the fact that it offers state-of-the-art compression efficiency in an open source, royalty-free package. As I wrote back in April 2016 in my guest post “Scalability, VP9, and what it means for WebRTC” in BlogGeek.Me, it’s the first such codec to bring state of the art scalability in browser-based video communication. Scalability has proven to be an essential tool for implementing high-quality multipoint video, and is supported in the royalty-bearing H.264 and HEVC codec standards.
Scalable coding means that the same video bitstream contains subsets of data, called layers, that allow you to reconstruct the original at different resolutions. Scalability can refer to a number of dimensions, namely temporal, spatial, or quality, with the first two being used in real-time communication applications.
Temporal scalability means that the same video bitstream allows you to take a subset of the data, and represent the video at different frame rates. Figure 1 shows how video encoding is done in real-time communication when no scalability is used, i.e., with a single layer. Each picture is using the previously coded picture as a reference; this way the encoder only needs to send the difference between successive pictures, thereby reducing the amount of data that it needs to transmit. These pictures are called “P” from the word “predicted”. The very first picture does not use prediction from a previous picture, and is referred to as an intra or “I” picture. A limitation is that in order to decode a picture, one must have received all the preceding pictures in the chain. This picture coding structure is typically referred to as IPPP, from the sequence of picture types it is constructed from.
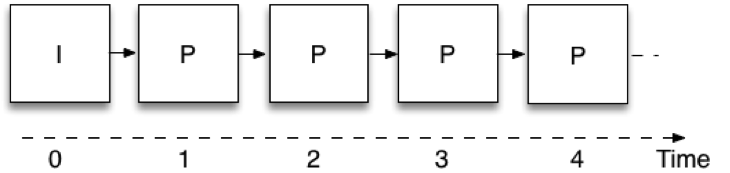
Figure 1: Single layer coding
Figure 2 shows how encoding is done when three temporal layers are used. The pictures are shown with a vertical offset to easily identify the different layers. Let’s assume that the full frame rate is 30 frames per second (fps). The bottom layer (layer 0) encodes one of every four pictures, thereby providing a rate of 7.5 fps. Notice that this layer is encoded in the same way as in Figure 1 – the first picture is an I picture, and the following pictures are all P pictures (P0).
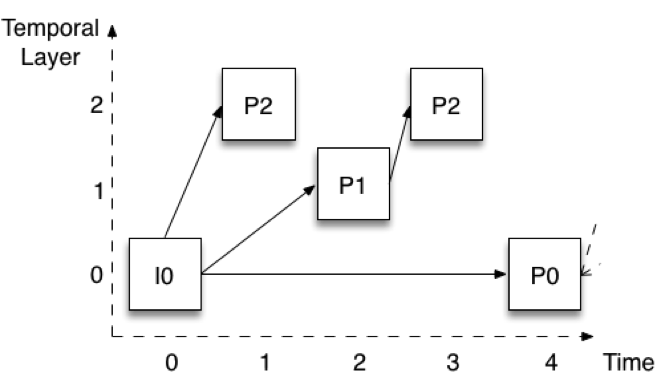
Figure 2: Temporal scalability with three layers
Layer 1 is then constructed by adding the pictures that are halfway between layer 0 pictures. In Figure 2 that would be picture P1. Notice that it is encoded using the immediately previous picture of layer 0. If we add the P1 pictures to the P0 pictures, we have a total rate of 15 fps. Finally, layer 2 is constructed by adding all remaining pictures (P2). These pictures are again encoded using the immediately previous pictures of a lower layer. For the first P2, this means I0 (or P0 later on in time) whereas for the second P2 it means the P1 at time 2. If we add the P2 pictures to the P0 and P1, we get a total of 30 fps.
This structure, called hierarchical P picture coding, has several useful properties. First, we can remove higher layers without affecting our ability to decode lower layers. It is then possible to reduce the frame rate at any given point in time with no signal processing. Second, the structure also allows us to go to a higher temporal layer at any point in time. For example, I can be receiving and decoding only layer 0 at 7.5 fps, but then decide to transition to full 30 fps and start doing so without any delay or additional signal processing. The structure also has significantly improved robustness. For example, only layer 0 needs to be received reliably.