
In this three part blog series, we are covering VP9, scalability, and Vidyo’s new, higher performance VP9 codec. In part 1, we discussed temporal scalability; today we’ll dive into spatial scalability.
Read More – Improving VP9 Without Changing It – Part 1
The second scalability dimension is spatial scalability, and it is a bit more complex. Assume as an example that we are encoding a video stream at 720p (i.e., each frame has 1280×720 pixels). Encoding it in a scalable way means that in addition to being able to represent the video at the highest 1280×720 resolution, we can also represent it at lower resolutions, e.g., 640×360 or 320×180. Notice that resolutions in this example happen to go down by powers of 2 in each dimension. Although this is not a requirement, ratios of 2:1 or 1.5:1 are typical in spatial scalability. The lowest resolution is called the base layer, and the data needed to construct each higher resolution are referred to as enhancement layers.
The terminology in this case reflects how the coded data are constructed. When encoding a picture, the encoder will scale down the original picture to the base layer resolution. It will then encode it, and use the reconstructed picture (the same picture that will be available at the decoder) as a reference to encode the higher resolution picture.
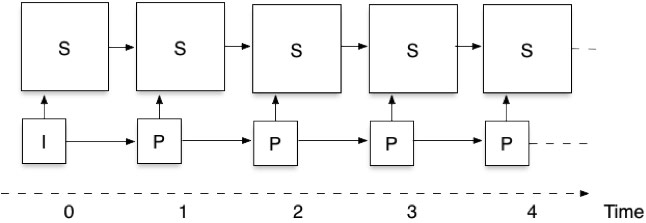
Figure 3: A video encoded with two spatial layers and one temporal layer
Figure 3 shows how the picture structure works using an example with two spatial layers and no temporal scalability (there is just a single temporal layer.) Notice that there are two sets of pictures or spatial layers. The bottom set is the low resolution pictures (the base layer) which are coded using the IPPP structure of Figure 1. In addition, we have the spatial enhancement layer (S), in which pictures are not only predicted from previous enhancement layer pictures, but also from the corresponding base layer picture. This dependency between layers is very important both for improving compression efficiency (the low resolution version of a picture is an excellent predictor for most parts of the high resolution picture) and improved error robustness (you can always use the low resolution version if the high resolution is damaged or lost.)
We can now combine the spatial and temporal scalability concepts in a single design, thereby allowing any combination of spatial resolutions and frame rates. Keeping with our example of two spatial layers and three temporal layers, Figure 4 shows what the picture structure looks like.
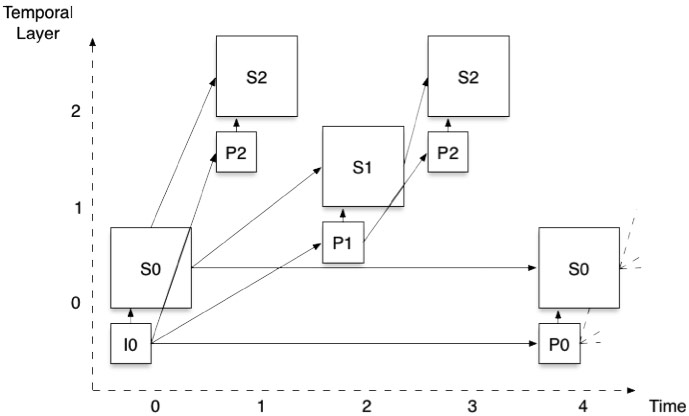
Figure 4: Combined scalability: two spatial layers and three temporal layers
Assuming a 720p 30fps original source, this structure allows us to obtain sets of layers that can provide any combination of 720p or 360p and 30, 15, and 7.5 fps. Most importantly, one can switch decoding between any quality point to another without having to inform the encoder or perform any signal processing.
The adaptability provided by scalable coding is a key part in implementing multipoint video using Vidyo’s patented Selective Forwarding Unit (SFU) architecture. The SFU can manipulate the video by selectively forwarding layer data according to user, network, or application needs. Scalability (both spatial and temporal) is also important for providing increased error robustness. You can read more details about the engineering design principles in my BlogGeek.me post.
While manipulating a stream that uses spatial and temporal scalability is very simple, creating one is not. If you look at Figure 4, every arrow that links two pictures or layers together hides thousands of individual decisions that need to be made by the encoder. The task of the decoder is much much simpler, since it only needs to act upon the instructions of the encoder.
You can think of the encoder as the music composer, and the decoder as the synthesizer that plays back the music according to the score created by the composer. Unlike the 88 keys of a keyboard, however, an encoder’s parameters look more like the cockpit of a commercial airliner (see Figure 5) – thousands of individual parameters need to be set in coordination for things to work well.

Figure 5: A380-800 cockpit (from Lufthansa’s web site)
Check back soon for part three, where we dive into performance comparisons and more.